Sagy Blog
Practical guides for engineering teams investigating incidents, reducing MTTR, debugging embedded systems, and preserving reusable engineering memory.
How to Reduce MTTR Without Hiring More Engineers
MTTR usually grows because incident context is scattered. A repeatable investigation workflow helps teams move faster before headcount becomes the only answer.

Wissem
Founder & CEO @ sagy
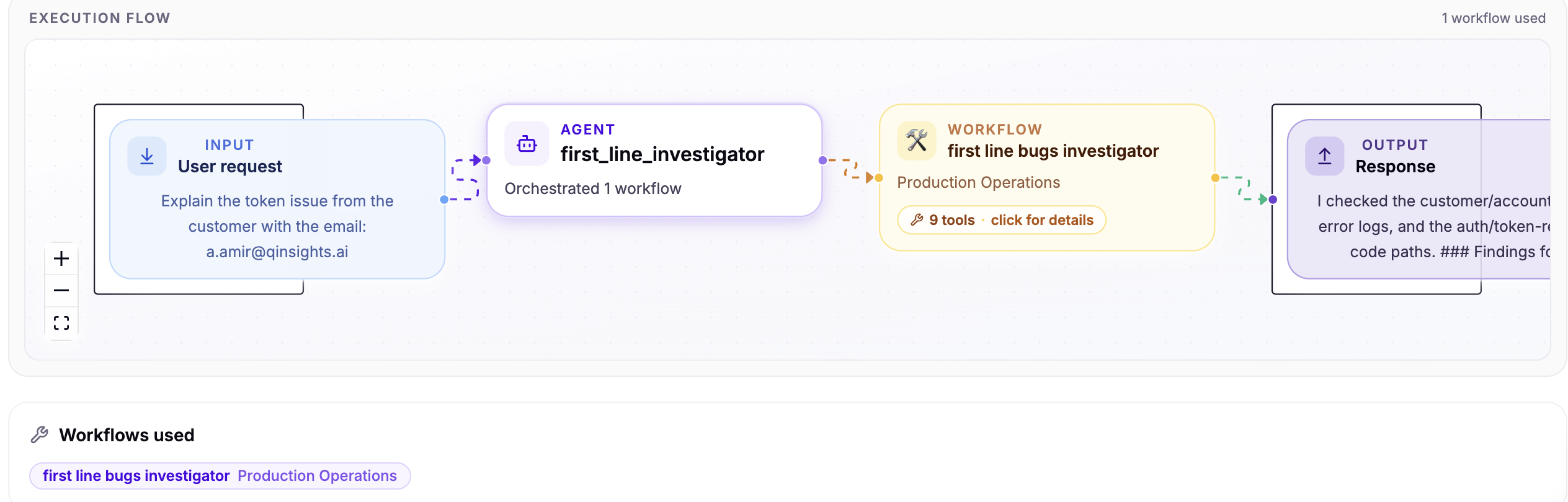
A Practical Root Cause Analysis Workflow for Engineering Teams
Root cause analysis gets better when teams separate symptoms, evidence, hypotheses, validation, and memory instead of jumping straight to the first explanation.
Wissem
Founder & CEO @ sagy

How to Investigate Incidents Across Slack, Jira, and GitHub
Modern incidents rarely live in one system. This workflow connects the conversation, ticket, code change, and prior decision trail.
Wissem
Founder & CEO @ sagy
Engineers Lose Days, Sometimes Weeks, Just Reproducing a bug seen by a customer. Here's Why.
Before debugging even starts. After 18 years in embedded systems, the real time sink isn't debugging, it's everything that happens before it.
Wissem
Founder & CEO @ sagy
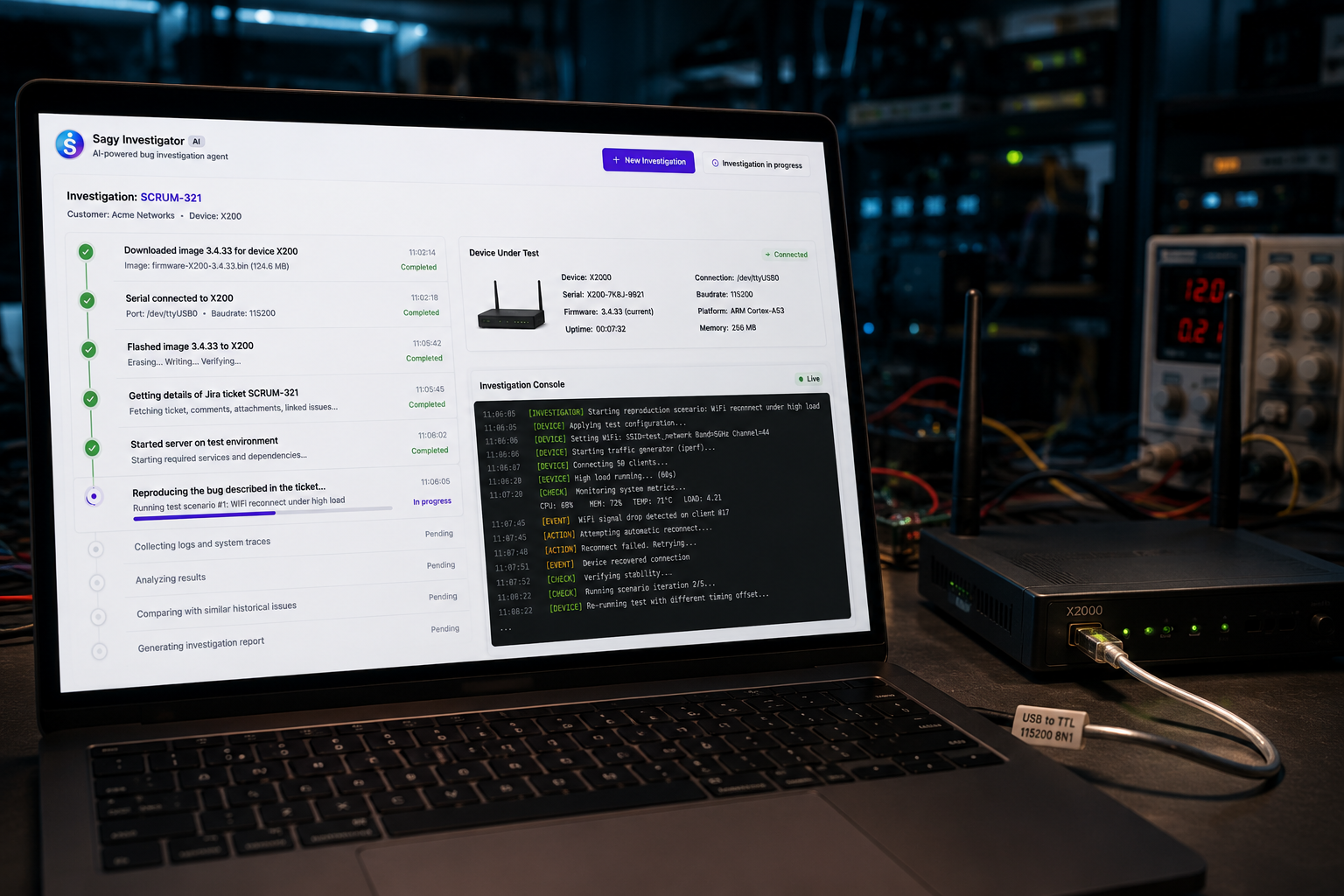
Customer Bug Investigation Workflow for Engineering Teams
Customer bugs move faster when support context, engineering evidence, reproduction steps, and final fixes stay connected.
Wissem
Founder & CEO @ sagy
How AI Agents Preserve Incident Knowledge for Engineering Teams
Incident knowledge disappears when it stays inside threads, tickets, and memory. AI agents can capture the investigation path while engineers work.
Wissem
Founder & CEO @ sagy
Why Static Knowledge Bases Like Confluence Are Failing Your Team (And What to Use Instead)
Static wikis weren't built for the speed of modern engineering. Here's why they break, and what an AI-native knowledge base looks like.
Wissem
Founder @ sagy


Stay Updated With Sagy
Get practical Sagy updates on incident investigation, root-cause workflows, and engineering memory.
We respect your inbox. Expect thoughtful updates, never spam.