How to Reduce MTTR Without Hiring More Engineers
MTTR usually grows because incident context is scattered. A repeatable investigation workflow helps teams move faster before headcount becomes the only answer.

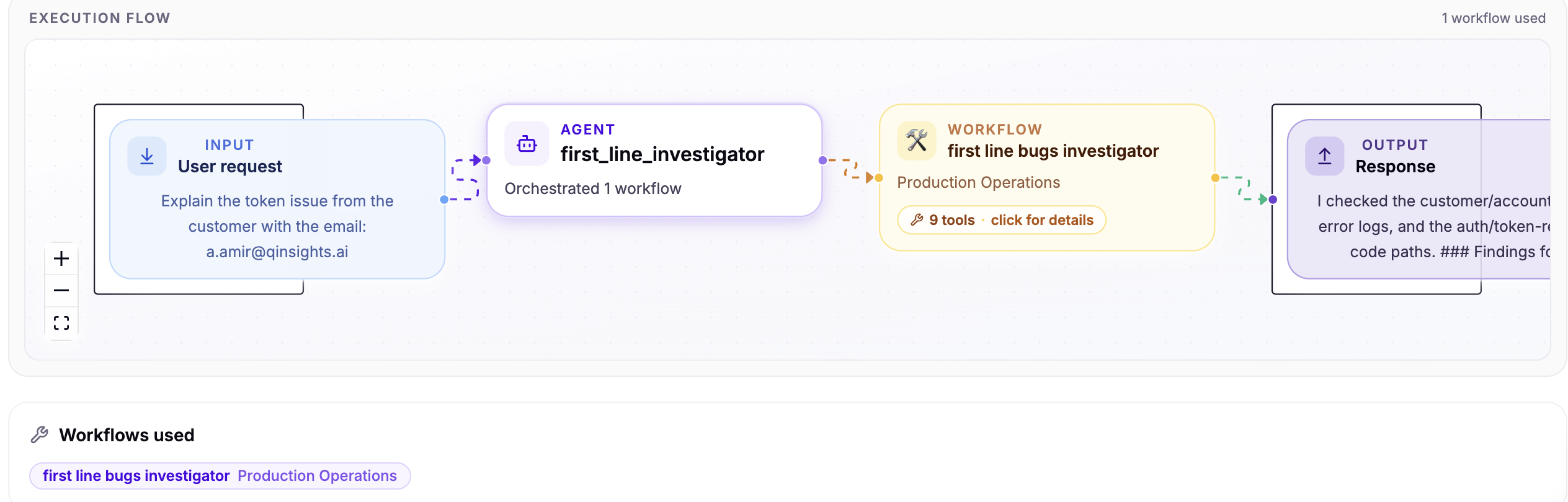
Reducing MTTR is rarely about asking engineers to type faster. The slow part is usually the time before the real fix begins: finding the right ticket, reading the Slack thread, checking recent pull requests, collecting logs, and asking who remembers the last time this happened.
That hidden investigation time is where engineering teams lose hours. When every incident starts from zero, even strong teams repeat the same context hunt again and again.
The better path is to make incident investigation repeatable. Sagy is built around that idea: an AI incident investigation agent gathers context, executes the known workflow, surfaces evidence, and turns the validated fix into reusable engineering memory.
Where MTTR Really Gets Lost
Most incident timelines include work that does not look like debugging:
- recovering context from Slack, Jira, GitHub, docs, and logs
- finding related tickets and past fixes
- checking which deploys or commits changed the affected system
- rebuilding the incident timeline for the next engineer
- waiting for senior engineers to remember old decisions
None of this is wasted work. It is necessary work. The problem is that it is repeated manually under pressure.
The Workflow That Reduces MTTR
A useful incident workflow has a simple shape: gather context, form hypotheses, attach evidence, ask for human validation, then preserve what worked.
Before Sagy
Every incident starts with a manual search across tools and people.
With Sagy
The first investigation packet already contains source links, likely causes, and next actions.
The result is not an automatic fix. The result is that engineers start closer to the truth.
What to Automate First
Start with investigation work that is high-value and repetitive:
- collecting ticket and conversation context
- matching symptoms to past incidents
- checking recent code changes
- collecting relevant logs and links
- drafting the first incident summary
Teams that connect this workflow to Slack, Jira, and GitHub can go deeper with the Slack Jira GitHub incident investigation agent.